Virtual-DOM中的diff算法
diff算法在Virtual-DOM中用于比较两个VNode树之间的不同,得到patch对象,之后根据patch对象来对真实DOM树进行修改。本文以React为例,介绍diff算法的过程。
Virtual-DOM的执行过程:
用JS对象模拟DOM树 -> 比较两棵虚拟DOM树的差异 -> 把差异应用到真正的DOM树上
首先来大概看一下React是怎么工作的:
1 | var MyComponent = React.createClass({ |
render得到的结果不是实际的DOM节点,而是轻量的JavaScript对象,称作Virtual-DOM。
React使用diff算法,来计算从上一个绘制到下一个绘制之间的最小路径。例如,如果我们安装<MyComponent first={true} />,之后用<MyComponent first={false} />取代他,最后再卸载掉。得到的DOM操作指令结果为:
第一步
- 创建节点:
<div className="first"><span>A Span</span></div>
第二步
- 替换属性:
className="first"byclassName="second" - 替换节点:
<span>A Span</span>by<p>A Paragraph</p>
第三步
- 删除节点:
<div className="second"><p>A Paragraph</p></div>
下面从以下几个方面来介绍diff算法:
逐层对比
找到任意两个树之间最小的修改步骤,是一个O(n^3)问题,这个复杂度过于高了。
由于web应用中很少出现将一个组件移动到不同的层级,绝大多数情况下都是横向移动。因此React尝试逐层的对比两棵树,在损失较小的情况下显著降低了比较算法的复杂度。
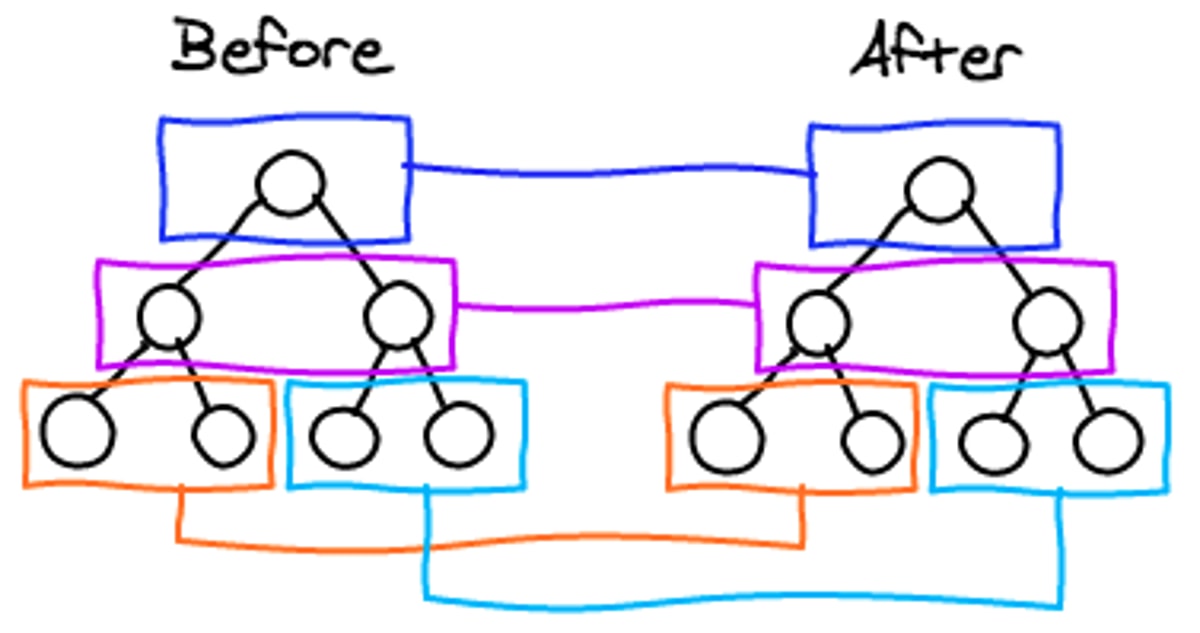
针对列表的优化
知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定DOM操作,让算法时间复杂度达到线性的(O(max(M, N))。
假设我们有一个组件,这个组件在一次迭代中生成5个组件,在下一次迭代中向列表中间插入一个新的组件。如果只有这些信息,很难找到两次迭代生成列表中组件间的对应关系。
React默认将前后两个列表中的组件按顺序关联起来。用户可以提供一个key属性,来帮助React找到正确的映射。
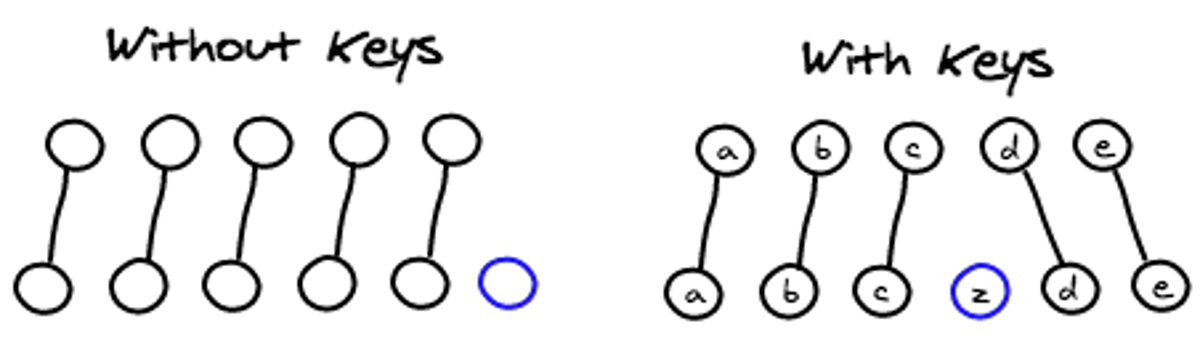
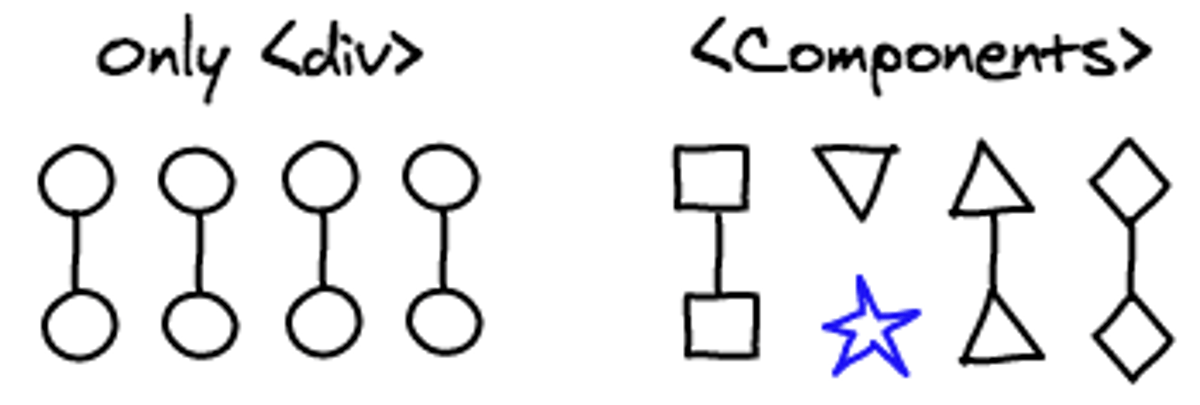
组件
两个不同组件可能都由div组成,React不会费时来比较两个组件间DOM组成的不同,因为他们在绝大多数情况下相关性很小。React只匹配具有相同class的组件。
事件委托
将事件添加到DOM节点非常耗时且占用很大内存。React使用事件委托,并且更进一步重新实现了一个符合W3C标准的事件系统。
React在文档根节点上添加了一个事件监听。当一个事件触发时,就可以得到目标DOM节点。由于每个React节点有一个独一无二的id来标记该节点的层级,因此可以直接使用string操作来得到所有父节点的id。通过将所有事件监听存储在一个hash map中。可以发现将事件绑定在Virtual DOM可以得到更好的效果。下面是一个事件在Virtual DOM中派发的例子:
1 | // dispatchEvent('click', 'a.b.c', event) |
React在起步阶段分配了一个event对象池,重复利用这些对象,可以显著减少垃圾收集。
渲染
Batching
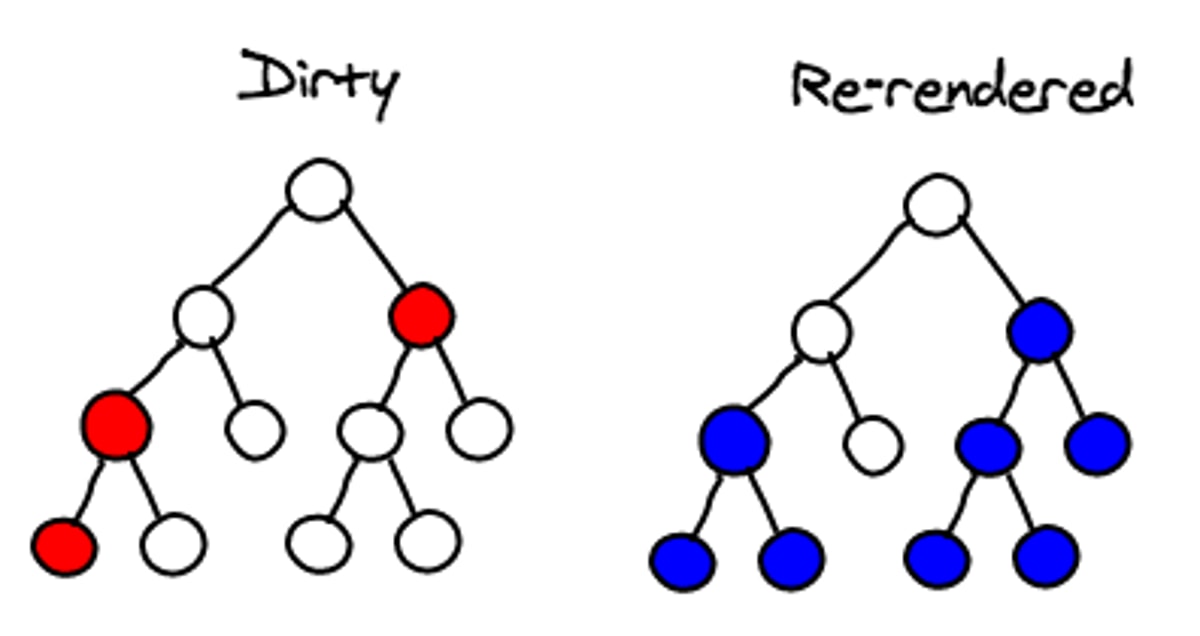
每次在一个组件中调用setState,React会把该组件标记为dirty。在事件循环的最后,React会重新绘制所有标记为dirty的组件。
batching表示在一个事件循环中,DOM只会被更新一次。
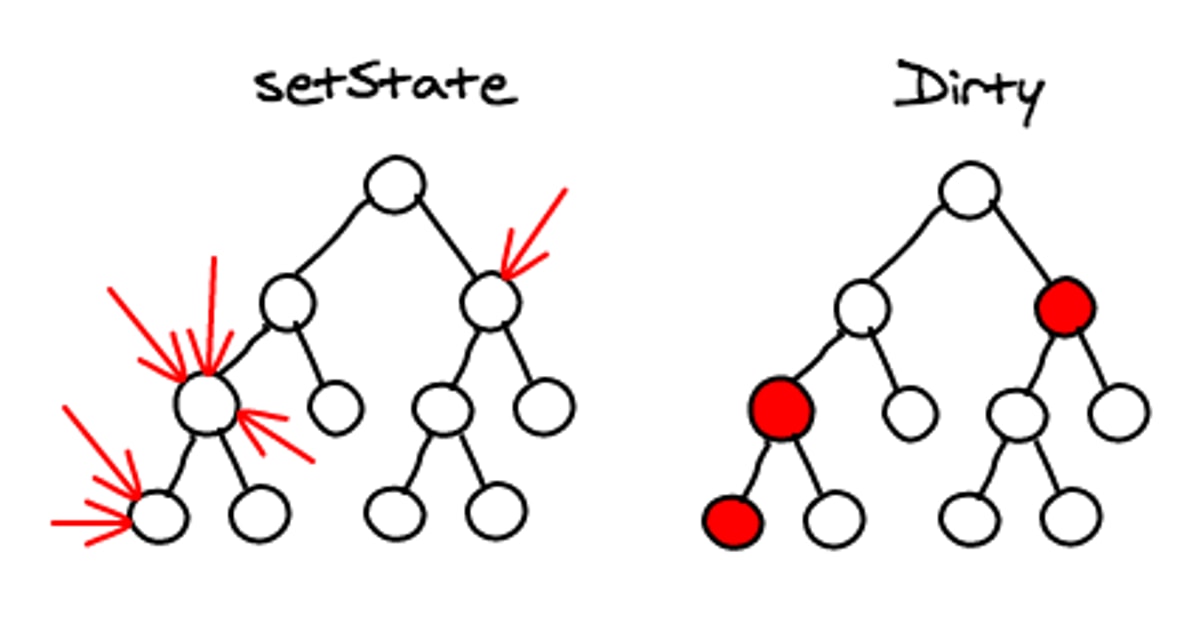
子树渲染
当在一个组件上调用setState时,这个组件会重新渲染他子元素的virtual DOM。如果在根元素上调用setState,那么整个React应用都会重新渲染。所有元素,即便没有改变,也会调用他们的render方法。这也许听起来非常低效,但是因为没有操作实际的DOM,在实践中效率是可以接受的。
以上基于两个出发点:
- JavaScript很快,足够管理整个界面的逻辑。
- 在编写React代码时,每次有改变发生,通常不会在root节点上直接调用setState方法。而是在收到改变事件的组件上调用
render方法。
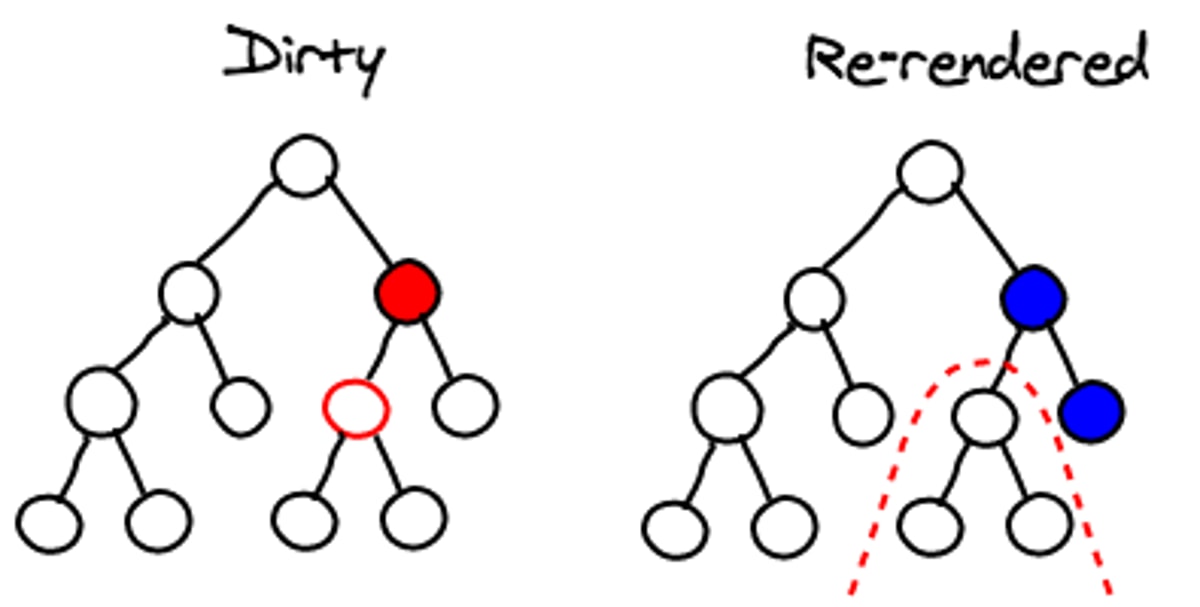
有选择的子树渲染
最后,React提供了shouldComponentUpdate方法来阻止子树重新渲染。如果适当使用,可以得到极大的性能提升。
但是,为了应用这个方法,需要进行JavaScript对象的对比。这就引发了很多问题:
- 对象间的比较应该是深比较还是浅比较;
- 如果是深比较,是应该使用immutable data还是深拷贝。
- 由于这个方法总是会被调用,因此要尽可能降低计算复杂度,尤其不能高于重新绘制这个元素的时间。
如果想要尽可能的提高效率。尽量少的调用setState,使用
shouldComponentUpdate来阻止庞大子树的重新渲染。
权衡折中
diff算法的优化是基于一定的假设的,如果这些假设不能得到满足,那么会对性能造成显著影响。
- The algorithm will not try to match subtrees of different component types. If you see yourself alternating between two component types with very similar output, you may want to make it the same type. In practice, we haven’t found this to be an issue.
- Keys should be stable, predictable, and unique. Unstable keys (like those produced by Math.random()) will cause many component instances and DOM nodes to be unnecessarily recreated, which can cause performance degradation and lost state in child components.
参考文献
- React’s diff algorithm,Facebook的人写的diff算法的讲解。
- Reconciliation,React文档中关于diff算法的讲解。