firecrawl 是如何工作的
关于如何让 LLM 理解站点,业界已经出现 https://llmstxt.org/ 规范,但如何自动化生成这些内容是一个难点。firecrawl 是一个使用 AI 来进行站点爬取的工具。
基本介绍
firecrawl 采用 C/S 架构,任务是执行在服务端的,前端通过 SDK 来调用,firecrawl 提供的 SDK 版本非常多,包括 Node.js、Python 以及 Rust 等。
SDK 负责提交任务,同时不断查询任务状态,进而拉取任务结果。
firecrawl 将服务端也进行了开源,所以我们可以自行部署,我们重点也是看 server 部分的代码。
Scrape 和 Crawl,以及执行队列
firecrawl 提供两个主要功能,scrape 用来对单个页面的内容进行提取,crawl 负责获取当前页面的各种子页面。
它们是两个相对独立的功能,在执行时 crawl 会在获取到所有 url 后分别调用 scrape 来获取页面内容。
所有这些任务,会使用一个基于 Redis 的 Node.js 队列来维护,这个项目叫做 bullmq,不过这里不是重点,我们主要看 firecrwal 是如何抓取链接,爬取页面内容的。

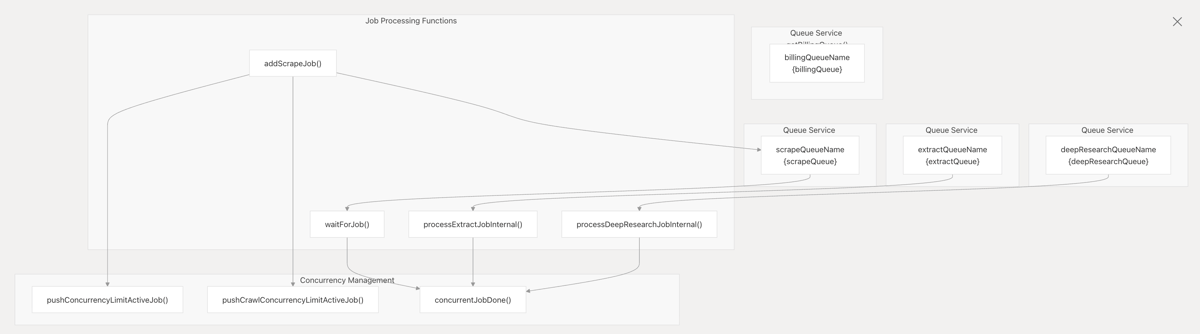
代码结构
代码仓库中,apps 下有多个目录,除了 SDK 类的:
api:服务端主要逻辑在这里,一个 express Node.js 服务,我们也要重点这里的代码。playwright-service-ts:一个单独的 playwright 服务,加载一个页面,返回页面的 HTML 内容。api 会请求这个单独的服务。redis:维护了 redis 的配置和启动脚本。ui/ingestion-ui:一个前端交互界面,不重要。
Scrawl 过程
调用 /scrawl api 会提交一个 job,进行一系列拼装以后将 job 提交进入了 BullMQ 队列,job 类型为 kick-off。apps/api/src/controllers/v2/crawl.ts
- scrape-worker 中的
processKickoffJob会进行 kick-off 类型任务的处理。这里会:- 对当前 url 生成一个 scrape job。
- 尝试从 sitemap 和之前的缓存中获取站点的其他链接,发起对应的 scrape job。
- 发起的 scrape job 会进一步触发
processJob方法,该方法用于执行单独的 scrape 操作,具体为:- 执行具体的
runWebScraper方法,进行页面的 scrape,具体我们在下方 Scrape 过程中分析。apps/api/src/main/runWebScraper.ts - 调用
startWebScraperPipeline方法,使用 WebCrawler 根据 HTML 内容静态分析拿到页面中的链接。apps/api/src/services/worker/scrape-worker.ts
- 执行具体的
可以看到整个 crawler 过程没有怎么用到 AI, 是一个静态分析找链接的过程。这里如果我们的页面跳转是使用 JS 来实现的,比如 location.href 或者隐藏在操作对象比如 sidesheet 中,就无法被抓取到。
Scrape 过程
Scrape 的入口在为 scrapeURL 在 apps/api/src/scraper/scrapeURL/index.ts 中,在执行过程中会根据文档类型尝试不同的 engine:

- index 用来快速获取之前已经抓取过的内容。
- fire-engines 用来访问 firecrawl 提供的一系列能力,这部分是不开源的。
playwright: Direct Playwright for self-hosted instancesfetch: Simple HTTP fetch for static content and APIspdf: Specialized PDF document processordocx: Microsoft Word document processor
这些 engine 会并行执行,有一个 race 和 validate 逻辑,他们只是普通的内容提取,例如 playwright engine 只是用浏览器加载页面之后拉取内容。
真正涉及到 LLM 的过程,体现在 transformer 里,这些虽然叫 transformer,但其实是一系列的处理 + 提取信息的流程,会挨个顺序执行,处理上面提取的页面内容:
deriveHTMLFromRawHTML- Cleans and transforms raw HTML using the Rust-based HTML transformerderiveMarkdownFromHTML- Converts cleaned HTML to markdown formatderiveLinksFromHTML- Extracts all links from the HTML contentderiveMetadataFromRawHTML- Extracts metadata like title, description, Open Graph tagsuploadScreenshot- Handles screenshot processing if requestedsendDocumentToIndex- Sends content to the search index (if enabled)performLLMExtract- Performs AI-powered structured data extractionperformSummary- Generates content summaries using LLMperformAgent- Handles SmartScrape browser automationderiveDiff- Generates change tracking diffscoerceFieldsToFormats- Removes unrequested output formatsremoveBase64Images- Strips base64 image data to reduce payload size
这里面跟 AI 相关的是 performLLMExtract 和 performAgent :
performLLMExtract根据现有内容使用 LLM 进行总结,同时会让 LLM 判断是否要启用 smartScrape(处理内容被遮挡需要交互后提取的情况)如果有就进行调用。performAgent用来处理用户自己输入的 prompt,其中也会调用 smartScrape。
至于这个 smartScrape,是一个远程服务,没有开源。但其实他的实现应该不难理解,一个 browser use agent,执行一些操作后提取页面内容。提示词是可以看到的:
1 | // Define common properties for reasoning and prompt |
局限性
链接的发现部分采用的 HTML 解析方案,不支持进行操作,对于需要一步步操作的场景,支持有限。比较适合静态展示的站点。