什么是 Transformer?
LLM 发展的飞快,现在每天都在使用基于 Transformer 的模型——ChatGPT、Claude、GitHub Copilot 等。
那么 Transformer 是什么?当我们输入一段文字后,这些模型是如何”理解”并生成回复的?
元旦放假,趁着有时间对 Transformer 进行了学习,这篇文章是学习过程中的笔记。我重点将从工程师的视角,来学习 Transformer 在推理阶段的工作原理。对于做工程来说,复杂的数学证明和训练算法是没有必要的,但通过代码类比和直观图解,可以让我们更加深入的理解 LLM 是如何运转的。下次再听到 混合专家模型(MoE) 等等,就不会只从形式上理解,而是有更加深入的算法对应关系了。
我发现这个网站非常有帮助,可以图形化的帮助理解 Transformer 的执行过程:transformer-explainer
Transformer 的整体架构
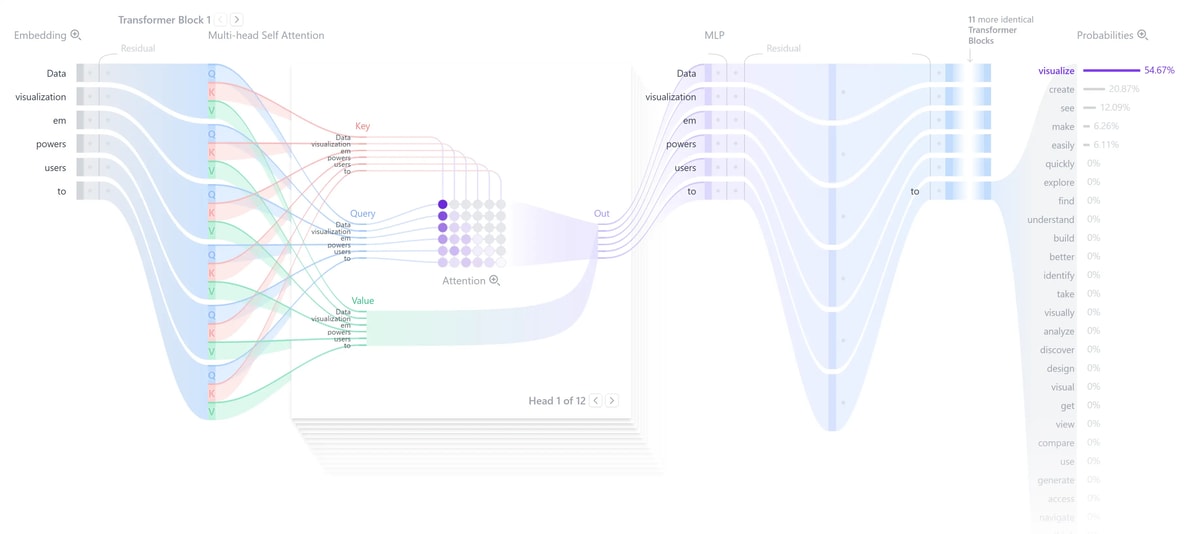
从高层面看,Transformer 的推理过程可以分为三个阶段:
1 | 输入文本 |
第一阶段:从文本到向量
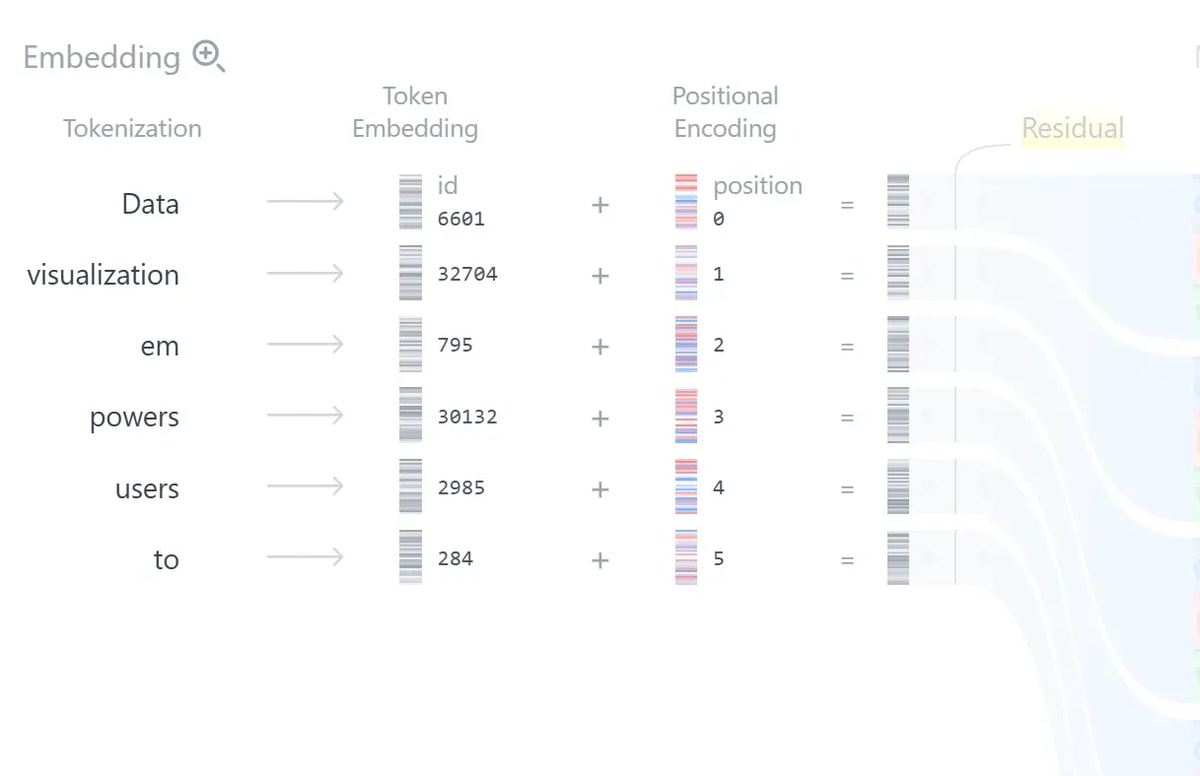
Tokenization:文本的离散化
当我们输入 “The cat sat on the mat” 时,Transformer 首先会将其切分成 Tokens(词元):
1 | 输入: "The cat sat on the mat" |
注意这里切分的方式是基于统计算法确定的,不是训练出来的。
Token Embedding:语义的向量化
每个 Token ID 会被映射到一个向量(通常是 512、768 或 1024 维)。这个向量是在训练过程中学习得到的,包含了该 Token 的语义信息。
1 | # 伪代码示例 |
关键理解:
这些向量不是随机的,相似的词会有相似的向量表示。例如,”cat” 和 “dog” 的向量在空间中会比较接近。
这里 embedding 中每个 token ID 对应的向量是通过训练得到的。在模型刚开始训练时(随机初始化阶段),每个 Token 对应的向量都是随机的乱码。随着模型不断学习(比如预测下一个词),误差会通过网络传回到 Embedding 层。模型会不断微调这些向量里的每一个数字,直到这些向量能够准确代表该词的语义。所以,训练完成后,语义相近的词(如“猫”和“狗”)在向量空间里的距离会变得很近。
Positional Encoding:记住顺序
Transformer 是并行处理的,它本身不知道单词的顺序。位置编码(Positional Encoding) 的作用就是给每个 Token 加上”位置信息”。
1 | Token Embedding: [0.2, -0.5, 0.8, ...] |
第二阶段:核心引擎 - Transformer Block
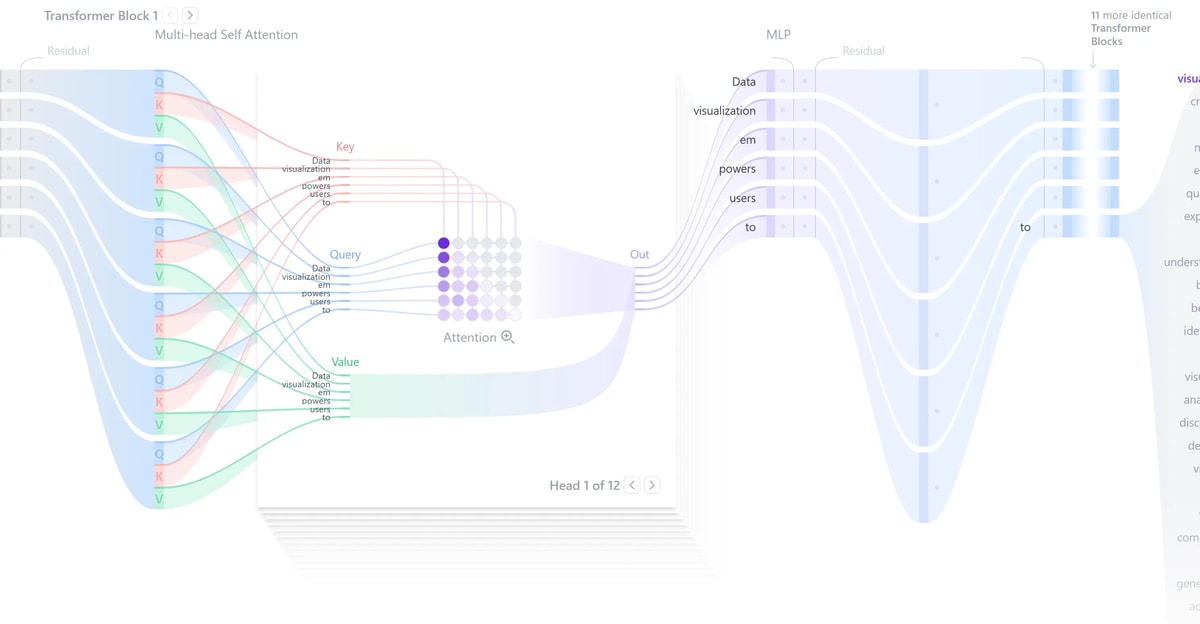
这是 Transformer 的核心部分,一个 Transformer Block 包含两个核心组件:
组件 1:Multi-Head Self-Attention(多头自注意力)
为什么需要 Attention?
先理解一个问题:为什么 Transformer 需要 Attention?
答:让每个 Token 能够”看到”句子中的其他所有 Token,从而理解上下文。
经典例子:
“The bank of the river” → bank 是”河岸”
“The bank deposit” → bank 是”银行”
人类通过上下文知道 “bank” 的含义,Transformer 通过 Attention 机制做到同样的事情。
QKV:注意力的三要素
Attention 的核心是 Q、K、V 三个概念,我们可以用搜索引擎来类比:
- **Query (Q)**:我想找什么(当前正在处理的 Token)
- **Key (K)**:每篇文章的标签(其他所有 Token 的特征)
- **Value (V)**:文章的具体内容(Token 的实际语义信息)
计算过程:
- 计算相似度:拿当前 Token 的 Q 与其他所有 Token 的 K 做点积
- 归一化为权重:通过 Softmax 将相似度转换为概率分布
- 加权求和:用权重乘以对应的 V,得到最终输出
工程实现细节:
Q、K、V 不是 Token 本身,而是通过三个线性变换矩阵计算得到的:
1 | # 每个 Token 的向量是 x (512维) |
这些矩阵 ($W_Q, W_K, W_V$) 是在训练过程中学习得到的,包含了模型”如何理解语言”的知识。
Multi-Head:多维度观察
如果只有一个 Attention,模型可能会错过一些细微的特征关系。Multi-Head Attention 的思想是:让多个”头”同时观察句子,每个头关注不同的方面。
类比:代码审查时,你可能需要:
- 安全专家审查 SQL 注入风险
- 性能专家审查算法复杂度
- 业务专家审查逻辑正确性
Multi-Head 就是这几位专家同时工作,最后汇总意见。
工程实现(重点):
虽然逻辑上有多个”头”,但实际代码中不是写多个循环,而是通过矩阵切分实现:
1 | # 假设 embed_dim=512, num_heads=8 |
这样,GPU 就可以并行计算 8 个头的 Attention,极大提升了效率。
此外上面的类比其实仅仅是数学计算的一个“解释”,在纯算法计算层面,就只是把线性变换矩阵切分成了多个,用不同的初始化值单独进行计算而已。
组件 2:Feed-Forward Network (FFN / MLP)
如果说 Attention 负责”让 Token 们相互交流”,那么 FFN 就负责”让每个 Token 独立思考”。
结构:
1 | 输入 (512维) |
为什么需要 FFN?
- 引入非线性:Attention 本质是加权求和(线性操作),没有激活函数就无法处理复杂逻辑
- 存储知识:研究表明,FFN 层存储了大量”事实知识”(如”巴黎是法国首都”)
- 逐 Token 处理:FFN 对每个 Token 独立处理,不依赖其他 Token
工程师类比:
- Attention = 团队会议(交换信息)
- FFN = 回到工位深加工(消化吸收)
这里 FFN 包含了大量的参数,约占整个 Transformer 参数的 2/3。如何升维,如何降维,都是由训练参数决定的。形象的理解可以是:从单个 token 视角来看,经过 attention 机制我们已经携带了跟自己这个 token 相关的其他 token 的信息,现在需要通过“知识“对这些信息进行整理发散(升维),充分思考后再进行归纳总结(降维)。所以 Attention 体现了“语言”,FFN 体现了“知识”。
完整的 Transformer Block
将两个组件组合起来,加上两个标准”零件”:
1 | class TransformerBlock(nn.Module): |
两个关键设计:
Residual Connection(残差连接):
x + Sublayer(x)- 作用:让底层信息能直达高层,防止梯度消失
Layer Normalization(层归一化):
- 作用:保证数值稳定性,防止计算溢出
堆叠多层:深度的重要性
一个 Block 够用吗?不够。现代 Transformer 会堆叠 12、32 甚至 96 层。
为什么要这么深?
每一层提取不同抽象级别的特征:
- 底层:识别词性(名词、动词)
- 中层:理解短语结构、指代关系
- 高层:理解逻辑、情感、隐含意图
类比:公司的层级管理
- 基层员工:处理具体数据
- 中层领导:理解局部逻辑
- 高层决策:基于全局信息做判断
第三阶段:输出生成
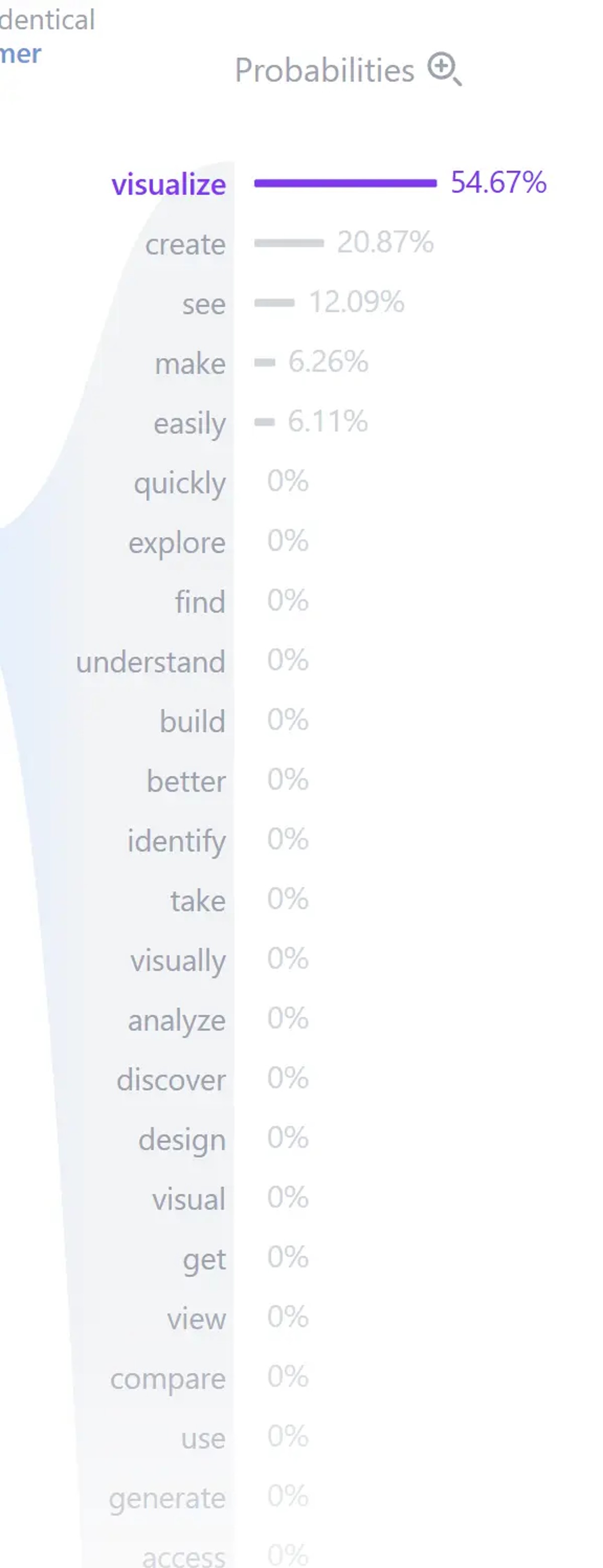
经过 N 层 Transformer Block 的处理,每个 Token 的向量已经融合了整个句子的上下文信息。
对于生成任务(如 GPT),最后一步是:
1 | # 1. 通过预测头映射到词汇表大小 |
对于理解任务(如 BERT 分类),通常会在第一个 Token([CLS])的位置接一个分类层。
工程实践要点
1. 计算复杂度的现实影响
核心问题:Self-Attention 的计算复杂度是 $O(n^2)$,其中 $n$ 是序列长度。
影响:
| 序列长度 | 注意力矩阵大小 | 计算量(相对) |
|---|---|---|
| 512 | 512×512 | 1x |
| 1024 | 1024×1024 | 4x |
| 4096 | 4096×4096 | 64x |
| 32768 | 32768×32768 | 4096x |
工程启示:
- 长文本推理会呈指数级增长成本
- 实际应用中考虑 RAG(检索增强生成)而非盲目增加上下文长度
2. 上下文窗口的限制
为什么有长度限制?
- 显存限制:存储 $n \times n$ 的注意力矩阵需要大量显存
- 位置编码外推性:模型在训练时只见过固定长度(如 2048),超出长度效果下降
- 性能考虑:长度越长,推理越慢
主流模型的上下文窗口:
- GPT-3.5: 4k / 16k tokens
- Claude 3: 200k tokens
- GPT-4 Turbo: 128k tokens
3. 推理优化技术
Flash Attention:通过优化 GPU 内存访问模式,大幅提升推理速度并降低显存占用。
KV Cache:在生成任务中缓存 K、V 矩阵,避免重复计算。
量化(Quantization):将模型参数从 FP32 降到 INT8,减少内存占用和推理时间。
4. 混合专家模型?
在 FFN 部分,由于需要升维和降维,计算量很大。一种优化方式是把 FFN 也切分成多个(多个专家),通过一个 router 在每次生成时只激活其中的两个,从而降低计算量。逻辑上解释就是每个切分出的 FFN 部分是一个专家,每次只需要激活需要的专家。(但算法上都是纯数学训练的结果,没有预定义 xxx 专家这种东西)
推荐资源:
- The Illustrated Transformer - 视觉化入门
- Transformer Explainer - 交互式可视化
- Hugging Face NLP Course - 实战课程